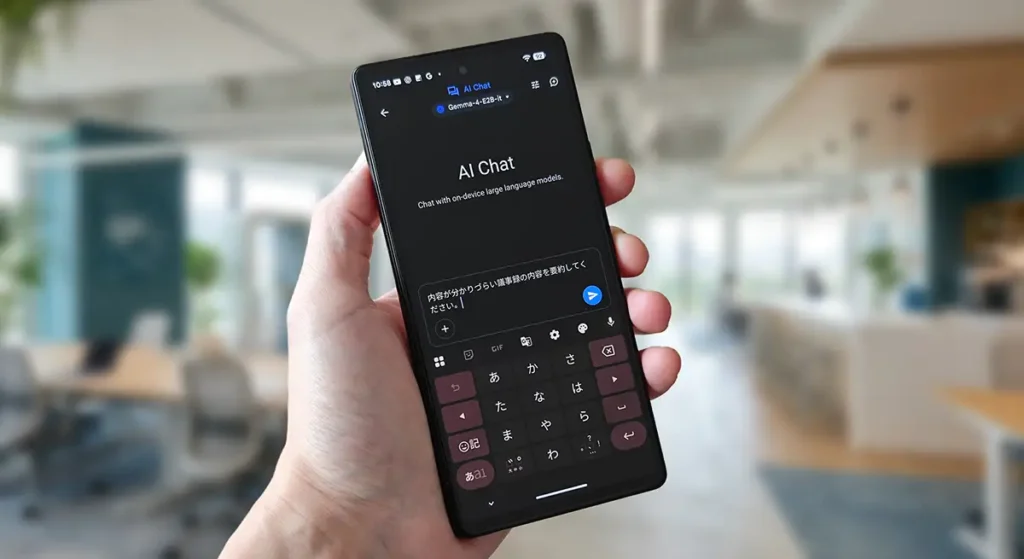
Googleは2026年4月2日、オープンサービス『Gemma 4』をリリースしました。AIと言えば『ChatGPT』『Gemini』を想像する人が多いと思いますが、これらは言ってしまえば『完成品』のAIアシスタントサービス。クラウド処理が前提となるので、利用するには『インターネット接続(クラウド)』が必須となります。
対するGemma 4は『オンデバイス(オフライン環境)』で動作。ChatGPTやGeminiが完成されたサービスであれば、Gemma 4は自分の端末やアプリに組み込みやすい、調整しやすい『AIの中身』です。
AIアシスタントサービスは共通のプラットフォームを『使う』ことがメイン。しかしGemma 4では『自分用のAI』『デバイスに組み込んで育てる』といった要素を持たせることが出来るので、この部分も特徴と言えるでしょう。
『ChatGPT』『Gemini』を日常の会話相手として使っている人が多いと思いますが、Gemma 4は『仕事のアシスト』を得意とします。文章や資料をまとめて扱うことが出来るので、『議事録』『長文記事』『複数メモ』『長い指示書』を読み込んで整理・要約・比較などに最適。
クラウド処理のAI経由で『個人』『機密』情報が漏洩したというニュースが定期的に報道されていますが、先述している通りGemma 4は『オンデバイス(オフライン環境)』で動作。情報漏洩を防ぎローカルで処理出来るのも大きな強みと言えるでしょう。
Googleは2026年4月2日、オープンモデルの新シリーズ『Gemma 4』を発表しました。Gemma 4は、Google公式でopen models、open-weights modelsとして案内されているAIモデルです。
AIと聞くと『ChatGPT』や『Gemini』を思い浮かべる人が多いと思います。これらは、一般ユーザーがそのまま使える完成されたAIアシスタントサービスです。普段の会話、質問、要約、アイデア出しなどを、主にクラウドを使って手軽にこなせるのが強みです。
それに対してGemma 4は、自分の端末やアプリに組み込みやすいAIモデルという立ち位置です。Google公式でも、Gemma 4は自分のハードウェア上での利用や、on-device / edge環境での活用を強く意識したモデルとして紹介されています。
分かりやすく言えば、ChatGPTやGeminiが『そのまま使う完成品』なら、Gemma 4は自分用に組み込み、調整し、育てていけるAIの中身です。Gemma 4はopen weights(学習済みのAIモデルのパラメータ)で提供されており、開発者は自分の用途に合わせてチューニングしやすいのも特徴です。
Gemma 4が向いているのは、単なる雑談よりも、長い文章や資料をまとめて扱う作業です。Google公式によると、Gemma 4はadvanced reasoning(高度な推論)やagentic workflows(高度なAI活用プロセス)を意識して設計されており、長文の整理、要約、比較、複数手順の処理などで力を発揮しやすいモデルです。また、Gemma 4は最大256Kトークンの長いコンテキストに対応。140以上の言語をサポートし、テキストに加えて画像入力も扱えます。
さらに、Gemma 4はローカル環境で活用しやすい点も魅力です。クラウドへ送信する前提のAIサービスと比べると、端末内で処理する設計にしやすいため、『外部送信のリスクを減らしやすい』というメリットがあります。


AndroidスマートフォンでGemma 4を使う簡単な方法(設定)
ここからはAndroidスマートフォンで『Gemma 4』を使えるようにする簡単な手順を紹介していきます。
1.Google Playから『Edge Gallery』をダウンロードしてインストール
Google AI Edge Galleryは、Gemma 4をスマホ上で手軽に試せる公式アプリです。

2.ホーム画面からEdge Galleryを開く

3.Edge Galleryトップ画面左上の横3本線アイコンから『Models』を選択

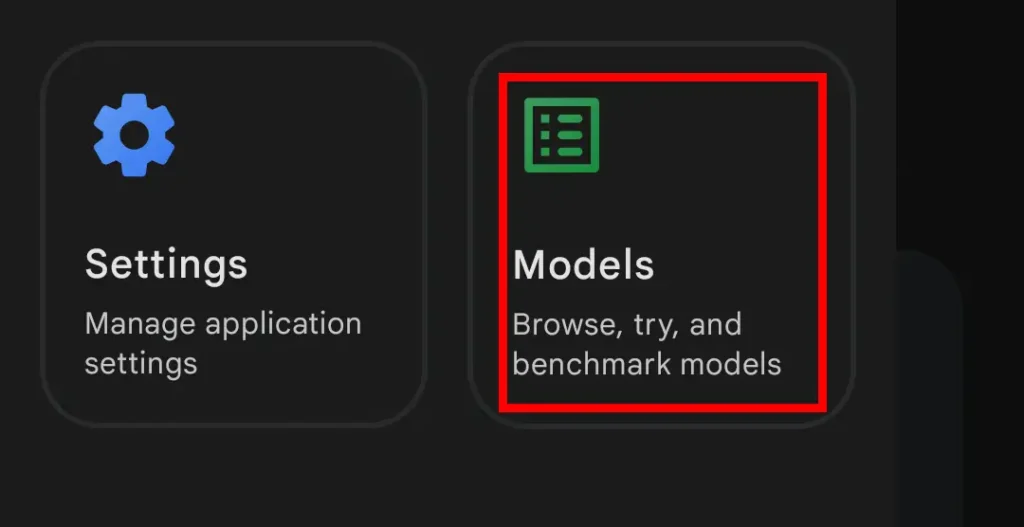
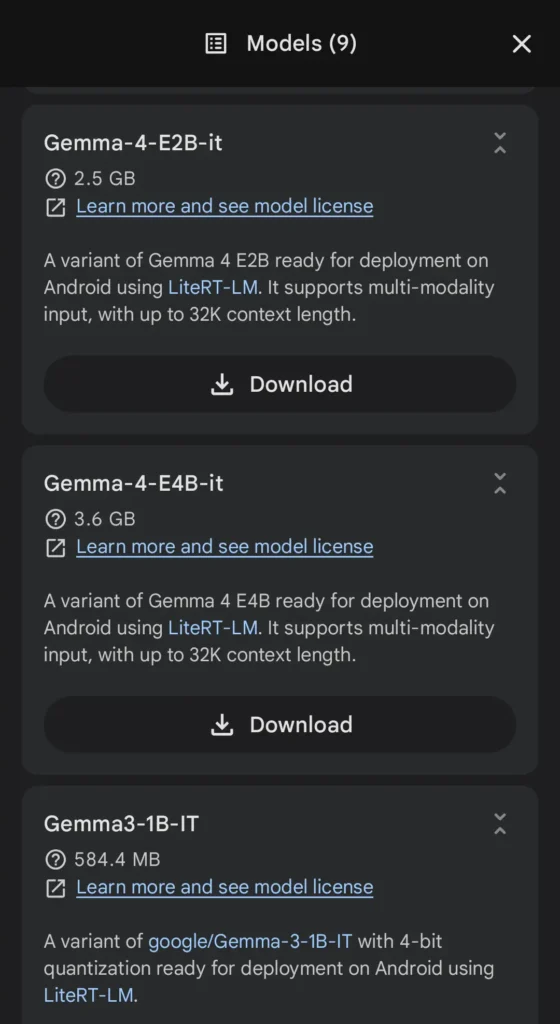
4.一覧から使用するモデルをダウンロード
Gemma 4はハードウェア要件に合わせた複数サイズがあり、Google公式は小型のE2B/E4Bから、大きい31Bや26B A4Bまでを案内。ハード性能に見合わないモデルをダウンロードすると『動作が重くなる』可能性があります(Pixel 6a[6GB/128GB]にGemma 4 E4Bを入れたらフリーズ)。
| 端末のざっくり条件 | 適したモデル | 使い方のイメージ |
|---|---|---|
| エントリー〜ミドルクラス向き(メモリ6〜8GB前後) | Gemma 4 E2B | まずは短文チャット、軽い要約、簡単な質問応答向け |
| ミドルクラス上位向き(メモリ8〜12GB前後) | Gemma 4 E2B / E4B | 実用寄り。長めの要約、少し重い推論、オンデバイス用途を試しやすい |
| ハイエンド向き(メモリ12GB以上) | Gemma 4 E4Bを優先 | スマホで現実的に狙うならこのあたりが本命。応答速度と実用性のバランスが取りやすい |
| PCでの使用 | Gemma 4 31B / 26B A4B | より重い推論、複雑な仕事、開発用途。本格運用向け |
5.使用モデルのダウンロードが完了したら、Edge Galleryのホーム画面から使用する機能を選択
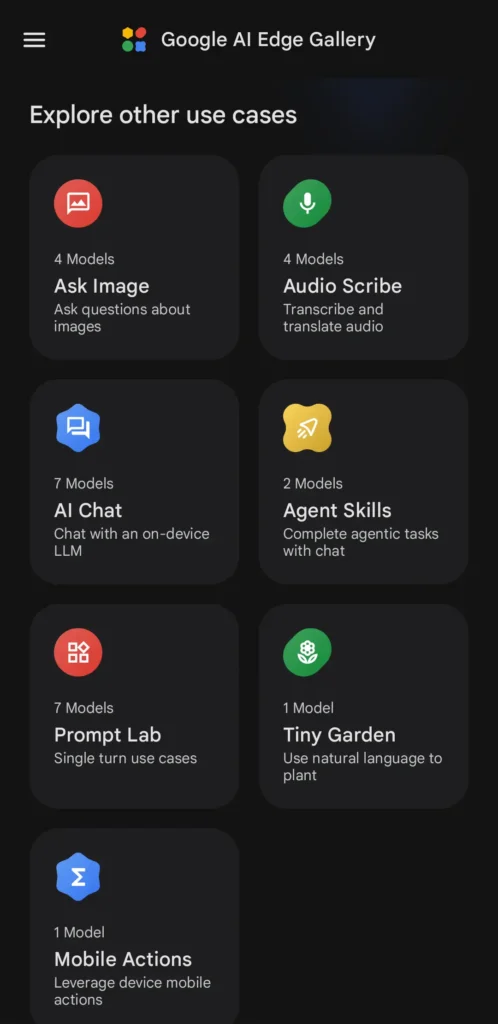
| 項目 | 何ができるか |
|---|---|
| Ask Image | カメラや写真を使って、物体認識、画像説明、視覚パズルの解析などができます。 |
| Audio Scribe | 音声を文字起こししたり、翻訳したりできます。公式ではリアルタイム処理も案内されています。 |
| AI Chat | 端末上のLLMと複数ターンで会話できます。Gemma 4対応モデルではThinking Modeも使えます。 |
| Agent Skills | AIにツールを持たせて、Wikipedia参照、地図、要約カード表示などを組み合わせた作業型の使い方ができます。 |
| Prompt Lab | 単発プロンプトを試したり、temperatureやtop-kなどの設定を変えて挙動を比較できます。 |
| Tiny Garden | 自然言語で指示して遊ぶ実験的ミニゲームです。FunctionGemma 270mのファインチューニング版が使われています。 |
| Mobile Actions | 端末のモバイル操作や自動タスクを、オフラインで動かせる機能です。これもFunctionGemma 270m系が使われています。 |
6.使用する機能(ここではAI Chat)を開いたら『→Try it』を選択
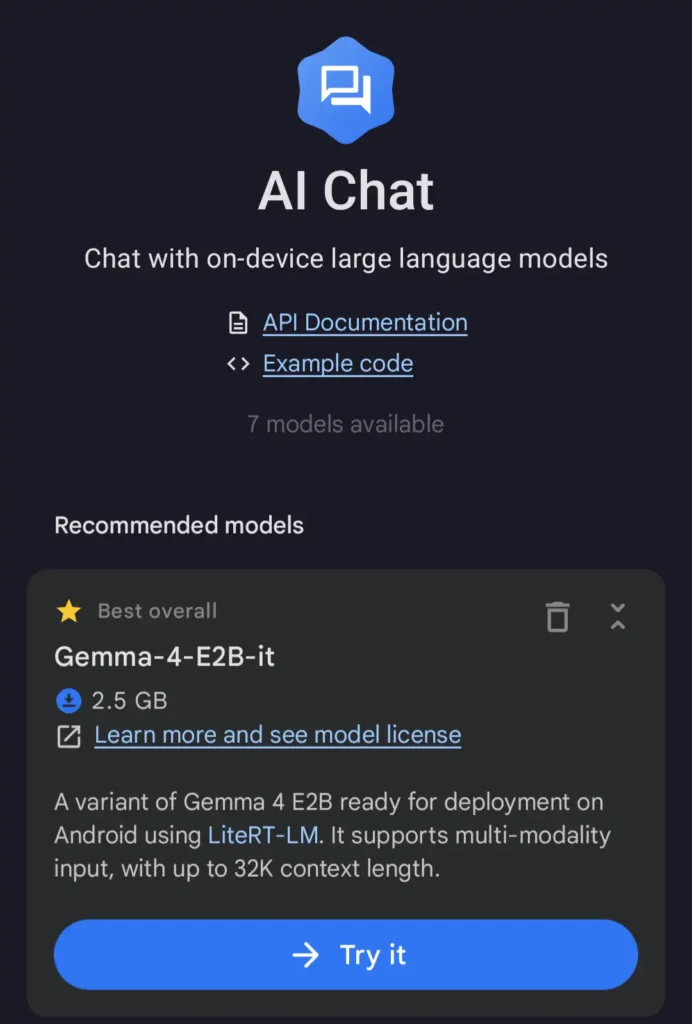
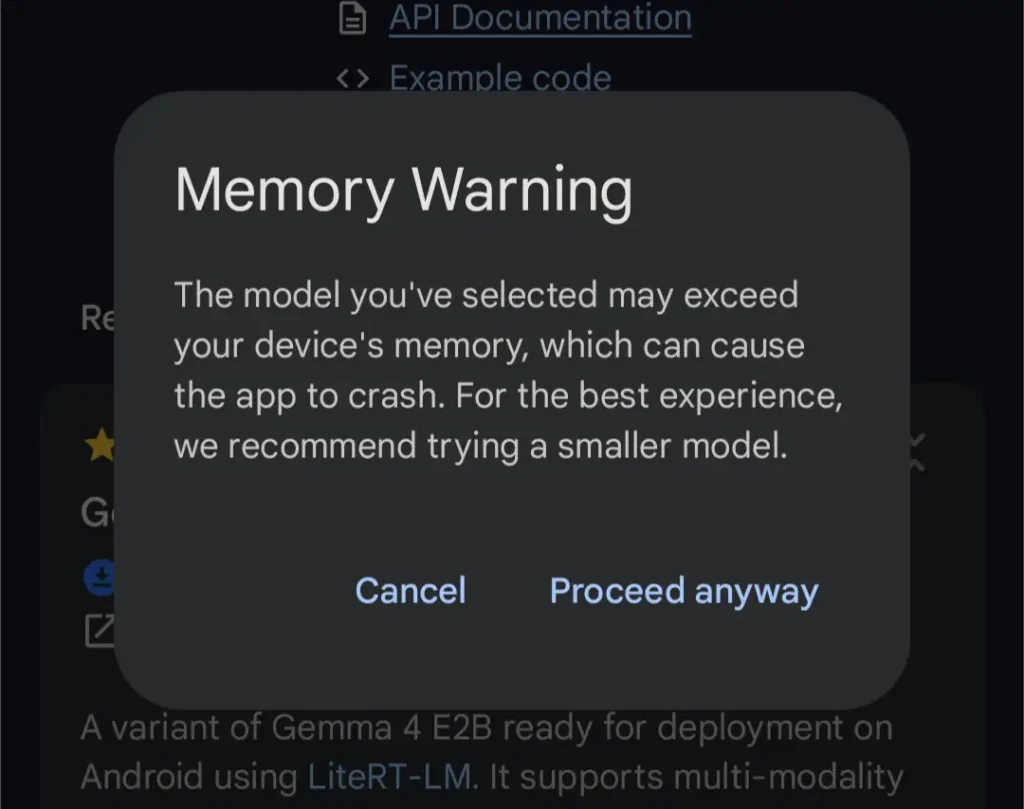
7.モデルの動き方を調整
右上のバーアイコンを選択して『Configurations』の画面を開きます。
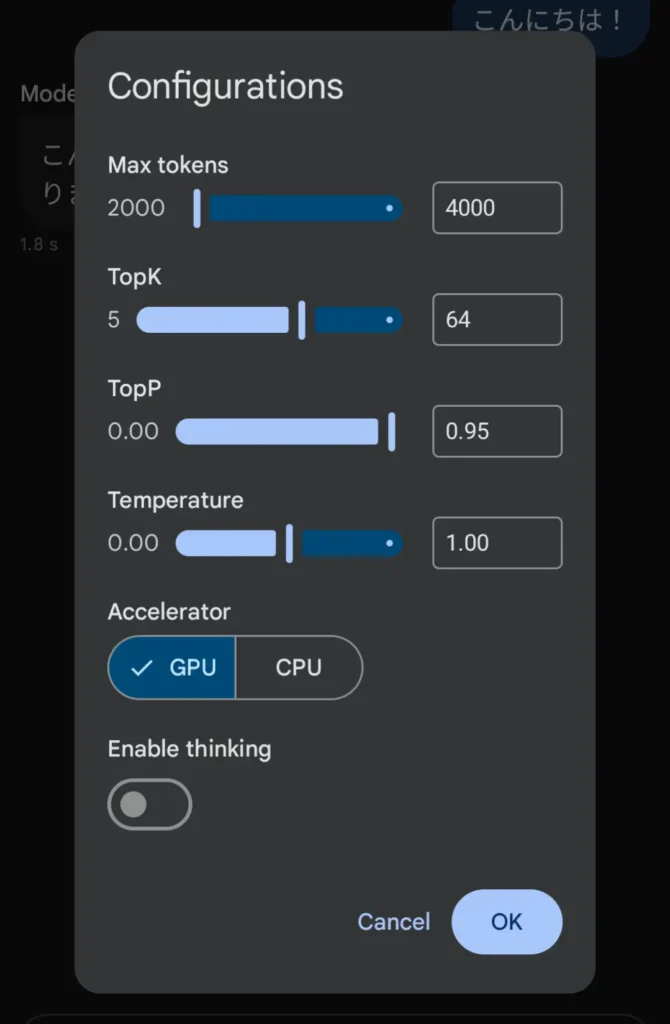
| 項目 | 各項目の意味(公式より) | 設定変更による影響 |
|---|---|---|
| Max tokens | Googleの生成パラメータでは、生成できるトークン数の上限です。1トークンはおおよそ4文字で、100トークンは約60〜80語に相当すると説明されています。なお、Google AI Edge の LLM Inference API では maxTokens をモデルが扱うトークン数の上限として説明しています。 | 返答の長さの上限。大きくすると長く答えやすいが、そのぶん重くなりやすい。 |
| TopK | 生成時に、次の1語を選ぶ候補を上位K個までに絞る設定です。Google公式では、1 だと最有力候補だけ、3 だと上位3候補から温度設定も使って選ぶと説明しています。 | どれだけ無難な候補だけから選ぶか。小さいほど堅め、大きいほど自由。 |
| TopP | 確率の高い候補から順に集めて、合計確率がPに達するまでを候補にする設定です。Google公式では、低いほどランダムさが減り、高いほどランダムさが増えると説明しています。 | どこまで候補を広げるか。低いと安定、高いと発想が広がりやすい。 |
| Temperature | Google公式では、ランダムさの強さを決める設定です。低いほど決定的で予測しやすく、高いほど多様で創造的になります。0 は最も確率の高い語を選ぶ寄りです。1.0 は推奨の開始値とされています。 | 答えの性格。低いと真面目でブレにくい、高いと自由で創作寄り。 |
| Accelerator(GPU / CPU) | Google AI EdgeのLLM Inferenceでは、Androidで CPU と GPU のバックエンドを選べると案内されています。 | 何で計算するか。一般にGPUの方が速いことが多いが、端末やモデルによっては不安定になることもある。 |
| Enable thinking | Edge Gallery公式READMEでは、Thinking Mode を有効にすると、モデルのstep-by-step reasoning process を見られると説明しています。現在はGemma 4ファミリーなど対応モデルから利用可能です。Gemma 4公式でも、全モデルがconfigurable thinking modes を持つと案内されています。 | 考える途中経過も見せるモード。答えは分かりやすくなることがあるが、遅くなりやすい。 |
関連リンク